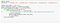
The answer is,
df['A'] = df['A'].map(addOne)from : https://stackoverflow.com/questions/36213383/pandas-dataframe-how-to-apply-function-to-a-specific-column
The answer is,
df['A'] = df['A'].map(addOne)from : https://stackoverflow.com/questions/36213383/pandas-dataframe-how-to-apply-function-to-a-specific-column
import pandas as pd
# Setup
df = pd.DataFrame([
{
"item":"truck",
"color":"red"
},
{
"item":"truck",
"color":"red"
},
{
"item":"car",
"color":"black"
},
{
"item":"truck",
"color":"blue"
},
{
"item":"car",
"color":"black"
}
])
df_grouped = df.groupby(["item", "color"]).agg(
count_col=pd.NamedAgg(column="color", aggfunc="count")
)
print(df_grouped)from : https://stackoverflow.com/questions/29836477/pandas-create-new-column-with-count-from-groupby
start_year, start_month, start_day, start_hour, start_min, start_sec, end_year, end_month, end_day, end_hour, end_min, end_sec, config_filename, region, limit, result = re.match(regex, my_raw_report).group(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)
start_year, start_month, start_day, start_hour, start_min, start_sec, end_year, end_month, end_day, end_hour, end_min, end_sec, config_filename, region, limit, result = re.match(regex, my_raw_report).group(*range(1,17))
If your csv files are very large say more than 100MB, then it would be very difficult to concatenate the csv files using conventional methods.
In Python we can use the library shutil to concatenate multiple large csv files into a single csv file.
Sample code is
import shutil
csv_files = ['source1.csv', 'source2.csv', 'source3.csv', 'source4.csv', 'source5.csv']target_file_name = 'dest.csv';
shutil.copy(csv_files[0], target_file_name)
with open(target_file_name, 'a') as out_file:
for source_file in csv_files[1:]:
with open(source_file, 'r') as in_file:
# if your csv doesn't contains header, then remove the following line.
in_file.readline()
shutil.copyfileobj(in_file, out_file)
in_file.close()
out_file.close()

To Test the code, download some sample large csv file (eg : https://www.stats.govt.nz/large-datasets/csv-files-for-download/)
Then make some copies of same files and run the above program.
from : https://medium.com/@princekfrancis/concatenate-large-csv-files-using-python-7e155e70f643
You can get what you want using CloudWatch Logs Insights.
You would use start_query and get_query_results APIs: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/logs.html
To start a query you would use (for use case 2 from your question, 1 and 3 are similar):
import boto3
from datetime import datetime, timedelta
import time
client = boto3.client('logs')
query = "fields @timestamp, @message | parse @message \"username: * ClinicID: * nodename: *\" as username, ClinicID, nodename | filter ClinicID = 7667 and username='simran+test@abc.com'"
log_group = '/aws/lambda/NAME_OF_YOUR_LAMBDA_FUNCTION'
start_query_response = client.start_query(
logGroupName=log_group,
startTime=int((datetime.today() - timedelta(hours=5)).timestamp()),
endTime=int(datetime.now().timestamp()),
queryString=query,
)
query_id = start_query_response['queryId']
response = None
while response == None or response['status'] == 'Running':
print('Waiting for query to complete ...')
time.sleep(1)
response = client.get_query_results(
queryId=query_id
)
Response will contain your data in this format (plus some metadata):
{
'results': [
[
{
'field': '@timestamp',
'value': '2019-12-09 17:07:24.428'
},
{
'field': '@message',
'value': 'username: simran+test@abc.com ClinicID: 7667 nodename: MacBook-Pro-2.local\n'
},
{
'field': 'username',
'value': 'simran+test@abc.com'
},
{
'field': 'ClinicID',
'value': '7667'
},
{
'field': 'nodename',
'value': 'MacBook-Pro-2.local\n'
}
]
]
}from : https://stackoverflow.com/questions/59240107/how-to-query-cloudwatch-logs-using-boto3-in-python