Sometimes, you have a lot of columns in your DataFrame and want to use only some of them.
Picking specific columns
df[‘col1]
This command picks a column and returns it as a Series


df[[‘col1’]]
Here, I chose the column and I get a DataFrame


df[[‘col1’, ‘col2’]]
This is the same command as above — but this time, I am choosing more than one column

Picking certain values from a column
df[df1[‘col1’] == value]
You choose all of the values in column 1 that are equal to the value.
df[df1[‘col1’] != value]
All of the values in column 1 that are not equal to the value.
df[df1[‘col1’] < value]
All of the values in column 1 are smaller than the value.
df[df1[‘col1’] > value]
All of the values in column 1 are bigger than the value.


df1[‘col1’] == value
Similarly to the above commands, just here you get Boolean values.


Picking certain rows
df.ix[index]
You can actually choose a row by using its index (the number on the far left).


df.ix[‘index name’]
This command does exactly the same thing as above but you use it when you have actually named your indices.
Deleting columns
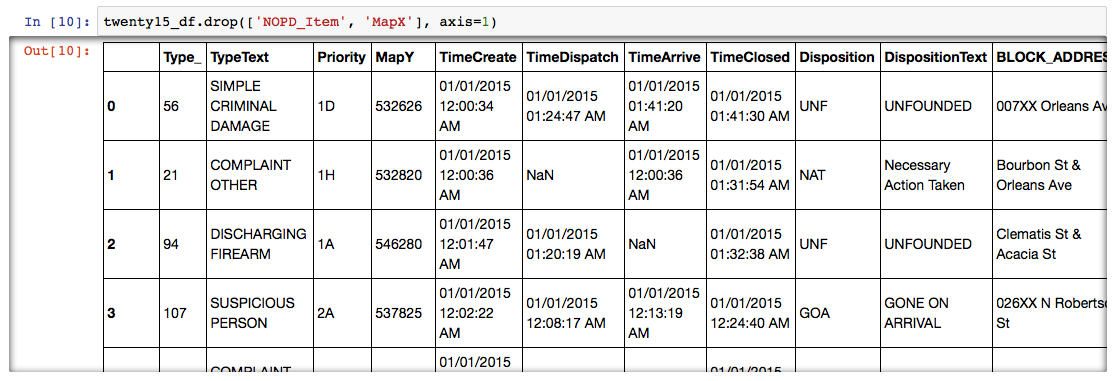
df.drop([‘col1’,’col2'], axis=1)
This command deletes specific columns from the DataFrame

del df[‘col1’]
This command deletes a specific column from the DataFrame and modifies it — so be careful how you use it.


All of the code can be found on my GitHub: https://github.com/kasiarachuta/Blog/blob/master/Choosing%20specific%20columns%20or%20rows%20from%20pandas%20DataFrame.ipynb
from : https://medium.com/@kasiarachuta/choosing-columns-in-pandas-dataframe-d0677b34a6ca