Use
renamedf.rename(columns={"by_week": "Last 7 days", "by_month": "Last 30 days"}).to_html()from : https://stackoverflow.com/questions/46096307/alias-for-column-in-pandas
renamedf.rename(columns={"by_week": "Last 7 days", "by_month": "Last 30 days"}).to_html()str(...) is the Pythonic way to convert something to a string.print ', '.join(str(x) for x in list_of_ints)text_file = open("your desired name.txt", "w")
text_file.write(file)
text_file.close()>>> import numpy as np
>>> from pandas import *
>>> df = DataFrame({'foo1' : np.random.randn(2),
'foo2' : np.random.randn(2)})
>>> df.to_html('filename.html')import io
import pandas as pd
from numpy.random import randn
df = pd.DataFrame(
randn(5, 4),
index = 'A B C D E'.split(),
columns = 'W X Y Z'.split()
)
str_io = io.StringIO()
df.to_html(buf=str_io, classes='table table-striped')
html_str = str_io.getvalue()
df.filter(regex='[A-CEG-I]') # does NOT depend on the column orderdf[ list(df.loc[:,'A':'C']) + ['E'] + list(df.loc[:,'G':'I']) ]['A','C','B'], then you could replace 'A':'C' above with 'A':'B'.df[['A','B','C','E','G','H','I']] # does NOT depend on the column order A B C E G H I
0 -0.814688 -1.060864 -0.008088 2.697203 -0.763874 1.793213 -0.019520
1 0.549824 0.269340 0.405570 -0.406695 -0.536304 -1.231051 0.058018
2 0.879230 -0.666814 1.305835 0.167621 -1.100355 0.391133 0.317467Str1 = "Apple Inc."
Str2 = "Apple Inc."
Result = Str1 == Str2
print(Result)
True
Str1 = "Apple Inc."
Str2 = "apple Inc."
Result = Str1 == Str2
print(Result)
False
Str1 = "Apple Inc."
Str2 = "apple Inc."
Result = Str1.lower() == Str2.lower()
print(Result)
True
Str1 = "Apple Inc."
Str2 = "apple Inc"
Result = Str1.lower() == Str2.lower()
print(Result)
False
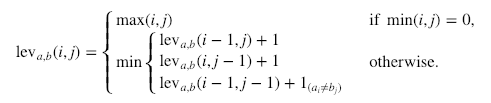
import numpy as np
def levenshtein_ratio_and_distance(s, t, ratio_calc = False):
""" levenshtein_ratio_and_distance:
Calculates levenshtein distance between two strings.
If ratio_calc = True, the function computes the
levenshtein distance ratio of similarity between two strings
For all i and j, distance[i,j] will contain the Levenshtein
distance between the first i characters of s and the
first j characters of t
"""
# Initialize matrix of zeros
rows = len(s)+1
cols = len(t)+1
distance = np.zeros((rows,cols),dtype = int)
# Populate matrix of zeros with the indeces of each character of both strings
for i in range(1, rows):
for k in range(1,cols):
distance[i][0] = i
distance[0][k] = k
# Iterate over the matrix to compute the cost of deletions,insertions and/or substitutions
for col in range(1, cols):
for row in range(1, rows):
if s[row-1] == t[col-1]:
cost = 0 # If the characters are the same in the two strings in a given position [i,j] then the cost is 0
else:
# In order to align the results with those of the Python Levenshtein package, if we choose to calculate the ratio
# the cost of a substitution is 2. If we calculate just distance, then the cost of a substitution is 1.
if ratio_calc == True:
cost = 2
else:
cost = 1
distance[row][col] = min(distance[row-1][col] + 1, # Cost of deletions
distance[row][col-1] + 1, # Cost of insertions
distance[row-1][col-1] + cost) # Cost of substitutions
if ratio_calc == True:
# Computation of the Levenshtein Distance Ratio
Ratio = ((len(s)+len(t)) - distance[row][col]) / (len(s)+len(t))
return Ratio
else:
# print(distance) # Uncomment if you want to see the matrix showing how the algorithm computes the cost of deletions,
# insertions and/or substitutions
# This is the minimum number of edits needed to convert string a to string b
return "The strings are {} edits away".format(distance[row][col])
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = levenshtein_ratio_and_distance(Str1,Str2)
print(Distance)
Ratio = levenshtein_ratio_and_distance(Str1,Str2,ratio_calc = True)
print(Ratio)
The strings are 2 edits away
0.8421052631578947
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = levenshtein_ratio_and_distance(Str1.lower(),Str2.lower())
print(Distance)
Ratio = levenshtein_ratio_and_distance(Str1.lower(),Str2.lower(),ratio_calc = True)
print(Ratio)
The strings are 1 edits away
0.9473684210526315
import Levenshtein as lev
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = lev.distance(Str1.lower(),Str2.lower()),
print(Distance)
Ratio = lev.ratio(Str1.lower(),Str2.lower())
print(Ratio)
(1,)
0.9473684210526315
from fuzzywuzzy import fuzz
Str1 = "Apple Inc."
Str2 = "apple Inc"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
print(Ratio)
95
Str1 = "Los Angeles Lakers"
Str2 = "Lakers"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(),Str2.lower())
print(Ratio)
print(Partial_Ratio)
50
100
Str1 = "united states v. nixon"
Str2 = "Nixon v. United States"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(),Str2.lower())
Token_Sort_Ratio = fuzz.token_sort_ratio(Str1,Str2)
print(Ratio)
print(Partial_Ratio)
print(Token_Sort_Ratio)
59
74
100
Str1 = "The supreme court case of Nixon vs The United States"
Str2 = "Nixon v. United States"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(),Str2.lower())
Token_Sort_Ratio = fuzz.token_sort_ratio(Str1,Str2)
Token_Set_Ratio = fuzz.token_set_ratio(Str1,Str2)
print(Ratio)
print(Partial_Ratio)
print(Token_Sort_Ratio)
print(Token_Set_Ratio)
57
77
58
95
from fuzzywuzzy import process
str2Match = "apple inc"
strOptions = ["Apple Inc.","apple park","apple incorporated","iphone"]
Ratios = process.extract(str2Match,strOptions)
print(Ratios)
# You can also select the string with the highest matching percentage
highest = process.extractOne(str2Match,strOptions)
print(highest)
[('Apple Inc.', 100), ('apple incorporated', 90), ('apple park', 67), ('iphone', 30)]
('Apple Inc.', 100)